
Unsupervised Learning
Unsupervised Learning is a type of machine learning where the algorithm is trained on data that has no labels or pre-defined categories. Unlike supervised learning, there is no “teacher” providing the correct answers; instead, the model explores the data to find its own hidden patterns and structures.
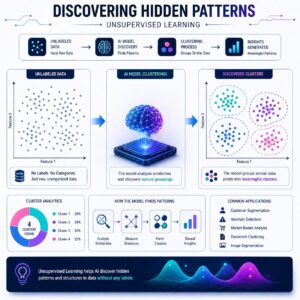
How It Works
The model acts as an explorer. It looks for similarities, differences, and anomalies in the raw dataset. Its goal is to model the underlying structure or distribution in the data to learn more about it.
Primary Techniques
1. Clustering
This is the most common task. It involves grouping data points so that objects in the same group (called a cluster) are more similar to each other than to those in other groups.
-
Example: A brand grouping customers into “Value Shoppers” vs. “Luxury Seekers” based on purchase history.
-
Common Algorithms: K-Means, Hierarchical Clustering, DBSCAN.
2. Association
This technique discovers rules that describe large portions of your data. It identifies “if-then” relationships between variables.
-
Example: A grocery store noticing that people who buy beer also tend to buy diapers (Market Basket Analysis).
-
Common Algorithms: Apriori, Eclat.
3. Dimensionality Reduction
This reduces the number of variables (features) under consideration by finding the most important ones. It simplifies the data without losing its essential “soul.”
-
Example: Compressing a high-resolution image or simplifying complex financial trends into a 2D graph.
-
Common Algorithms: Principal Component Analysis (PCA), t-SNE.
Key Differences
| Feature | Supervised Learning | Unsupervised Learning |
| Input Data | Labeled (Input + Output) | Unlabeled (Input only) |
| Goal | Predict outcomes / Classify | Find hidden patterns |
| Complexity | Simple; requires human labeling | Complex; requires more compute |
| Accuracy | Easy to measure | Subjective; harder to validate |
Real-World Applications
-
Anomaly Detection: Identifying fraudulent credit card transactions that don’t fit a user’s normal spending pattern.
-
Genetics: Grouping DNA sequences with similar patterns to identify hereditary diseases.
-
Recommendation Systems: Finding “neighboring” users with similar tastes to suggest new music or movies.
-
Data Preprocessing: Reducing noise in a dataset before feeding it into a supervised model.